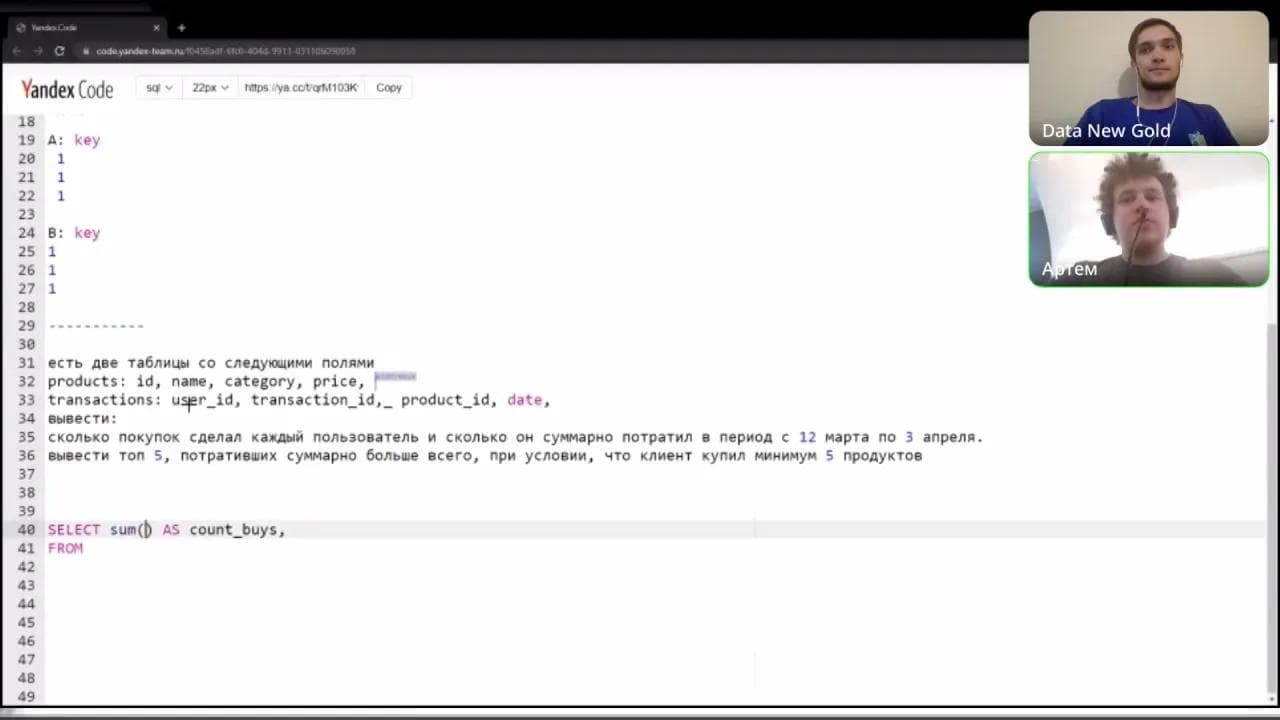
Ответ
Да, я работал с ClickHouse в проектах, где требовалась аналитическая обработка больших объемов данных в реальном времени. Использовал его как основное хранилище для логов и событий.
Основной опыт включает:
- Создание и оптимизация таблиц с движком
MergeTree, настройка партиционирования и сортировки для ускорения типичных запросов. - Написание агрегирующих материализованных представлений для предрасчета часто запрашиваемых метрик.
- Интеграция с Kafka через движок
Kafkaдля потокового приема данных. - Настройка репликации с использованием
ReplicatedMergeTreeдля отказоустойчивости.
Пример создания оптимизированной таблицы:
CREATE TABLE user_events
(
event_date Date,
event_time DateTime,
user_id UInt64,
event_type String,
parameters String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_date)
ORDER BY (user_id, event_time)
SETTINGS index_granularity = 8192;Ключевые преимущества, которые я использовал — это высокая скорость выполнения GROUP BY-запросов и эффективное сжатие данных.